Java Machine Learning(Java-ML)を使ってみよう
本チュートリアルの内容
■ 動作環境 の確認
前提とする環境
このチュートリアルでは、以下の環境を想定します。
- 使用PC:Windows8.1 Professional、Java Machine Learning Library 0.1.7
- 使用IDE: Eclipse Mars2 4.5.2
ライブラリの準備
本チュートリアルでは、Eclipseは既にインストール済みであると想定して説明を進めます。ということで、ここでは、使用するライブラリについてのみ、説明をします。今回使用するJava Machine Learning Libraryは、Sourceforgeよりダウンロードすることができます。今チュートリアルでは、バージョン0.17を使用します。以下のリンクからも、ダウンロードページに移行することができます。
ダウンロードしたzipファイルを解凍すると、ドキュメントやサンプル、ソースファイルやバイナリファイルが入っているのが確認できますが、ここでは、バイナリのライブラリファイルを使用することとします。解凍したフォルダごと、後から参照しやすい場所に置きます。ここでは、C:\lib\java\javaml-0.1.7という形で保存することとします。
後ほど、Eclipseからjarファイルを外部ライブラリとして参照する必要があるので、場所を忘れないようにしましょう。
■ ランダムフォレストを実装してみる
では、実際にライブラリを使ってみましょう。ここでは、機械学習のうち、ランダムフォレスト法を使ってみます。ランダムフォレスト法についての詳細は、他のサイトを参照していただきたいのですが、このランダムフォレスト法は、決定木を弱学習器として利用したアンサンブル学習となります。
学習と分類の精度の検証に、データが必要になるのですが、ここでは、有名なirisのデータを使わせていただきます。データは以下のリンクからダウンロードできます。
ダウンロードしたデータは、Eclipseのプロジェクトのフォルダに保存します。
では、実際にプログラムを作成します。まず、Eclipseで新しいプロジェクトを作成します。ここでは、JML_Sampleというプロジェクトを作成しました。
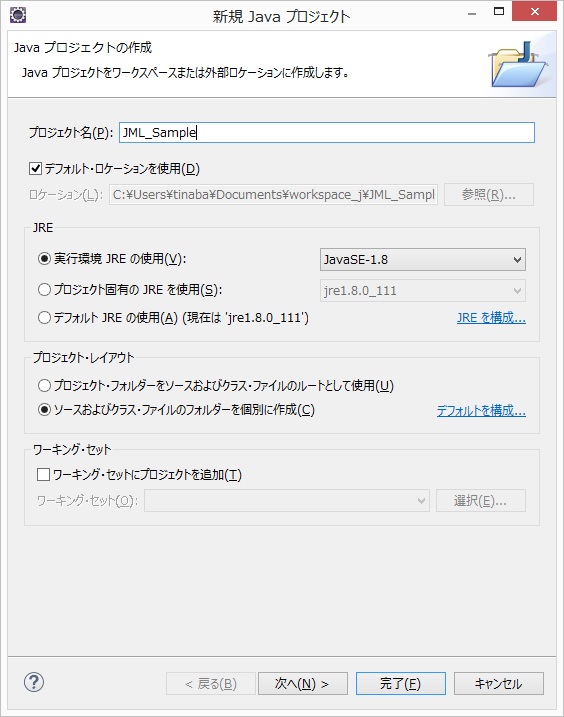
図 プロジェクトのスタート
次に、パッケージを作成します。先ほど作った、JML_Sampleプロジェクトのsrcでマウスを右クリックし、新規のパッケージの追加を選択します。ここでは、sampleというパッケージを作っておきます。
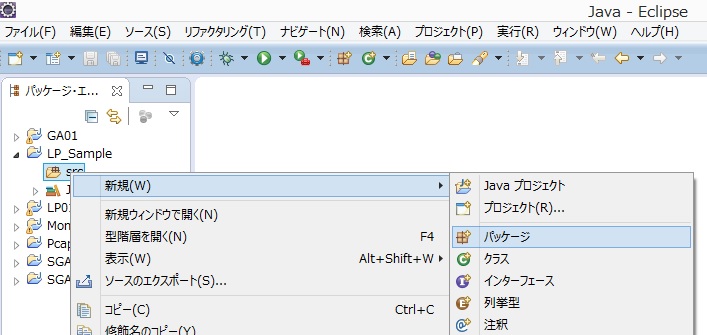
図 パッケージの作成
ここで、最初に使用するライブラリを外部ライブラリとして設定します。設定には、まず、プロジェクトで右クリックし、「ビルドバス」>「ビルドバスの構成」を選択します。
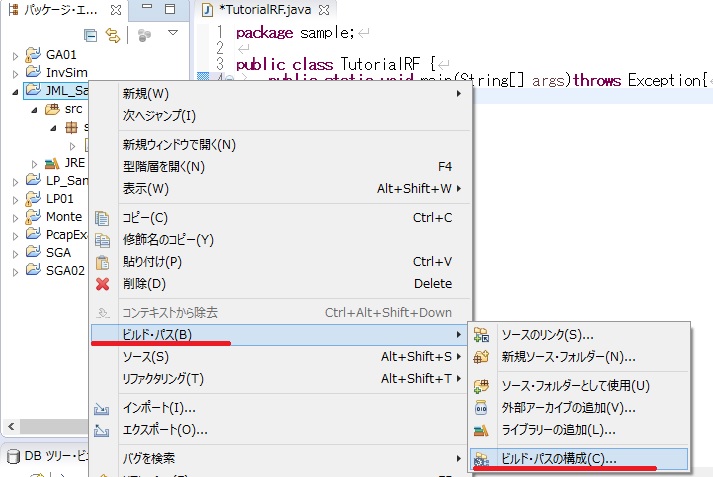
図 外部ライブラリ追加(1)
開いた画面から、「外部JARの追加」を選択します。
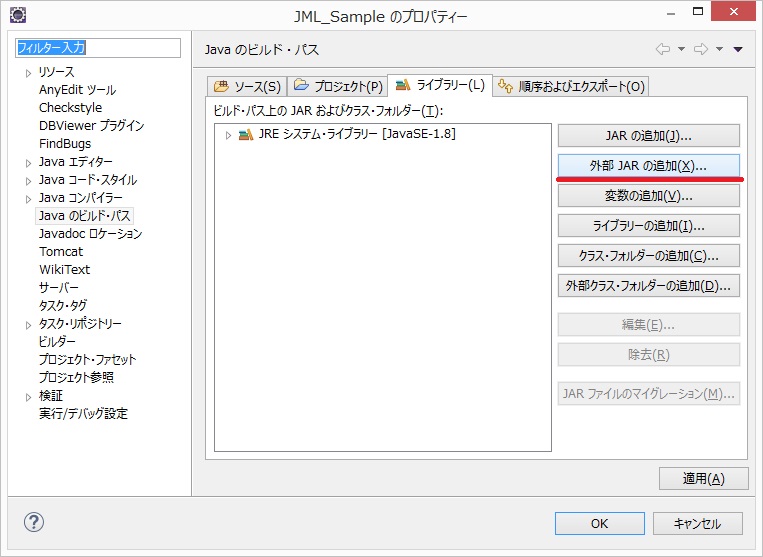
図 外部ライブラリ追加(2)
そして、先ほど保存したJava-MLのライブラリから、javaml-0.17.jarを選択します。
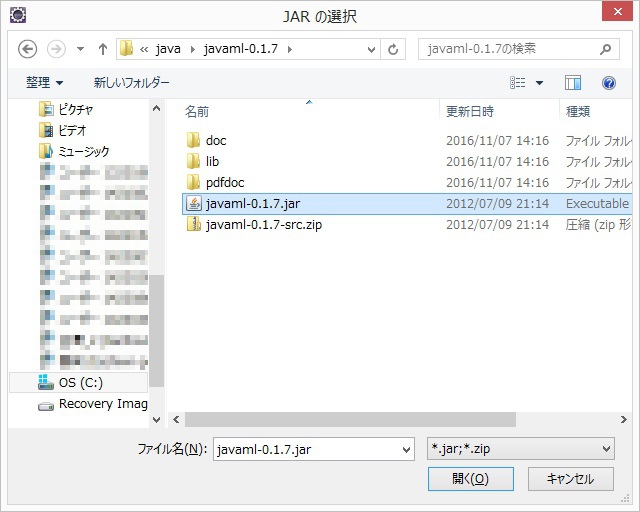
図 外部ライブラリ追加(3)
OKを押下した後、もう一回、「外部JARの追加」を選択し、今度は、libフォルダの中のajt-2.9.jarを選択します。
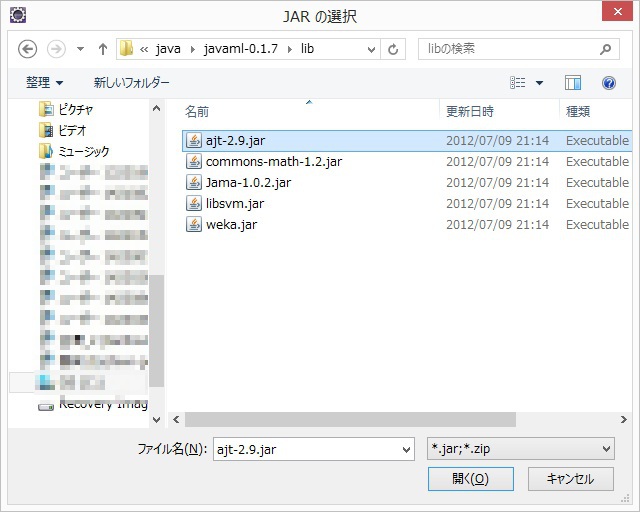
図 外部ライブラリ追加(4)
OKを押下すると、二つのライブラリが外部ライブラリとして追加されます。
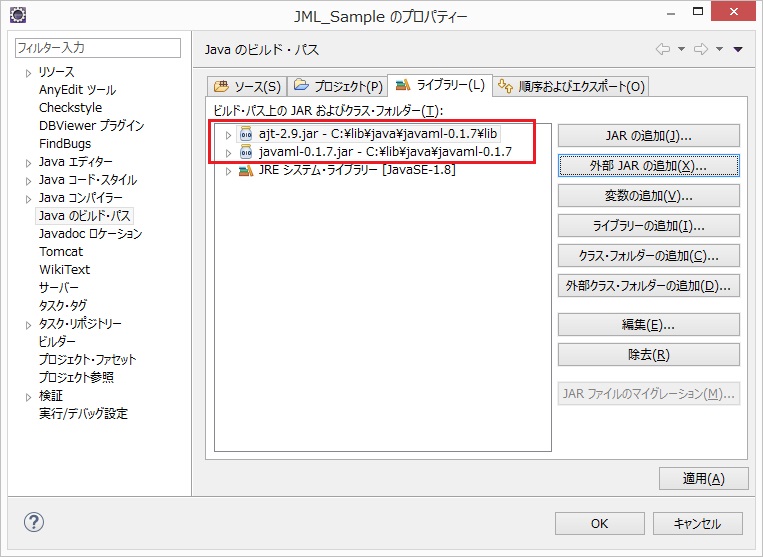
図 外部ライブラリ追加(5)
続いて、実際のクラスの作成ですが、ここでは、TutorialRF.javaという名前のクラスを作成します。
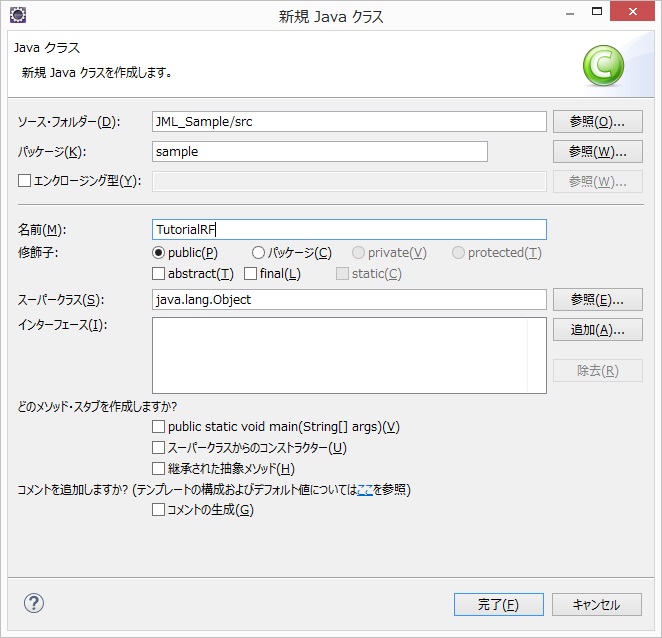
図 クラスの作成
プログラムは、非常に単純で、学習用データの読み込みと学習をまず行い、その後、同じデータを使って、分類結果の検証を行うだけです。ライブラリの使い方の説明だけですので、全てをmainメソッドに記述します。
まず、学習用データの読み込みですが、ここでは、Datasetクラスを用います。iris.dataは、カンマ区切りの4要素ですので、以下のように記述します。エラーが出来るかと思いますが、必要に応じて、ライブラリをインポートします。Eclipseでは、エラーの箇所にカーソルを合わせて、推奨されるライブラリをimportすれば、たいていの場合、エラーは消えます。
// 学習用データの読み込み
Dataset data = FileHandler.loadDataset(new File("iris.data"), 4, ",");
続いて、ランダムフォレストクラスのインスタンスを作成します。この時に引数として、作成する決定木の本数を整数として入力します。ここでは、10を入れておきます。そして、buildClassifierメソッドを用いて、学習を行います。引数は先ほど読み込んだデータとなります。
// ランダムフォレストの作成と学習
Classifier rf = new RandomForest(5);
rf.buildClassifier(data);
以上で、学習用データの読み込みと学習は終了です。
続いて、分類結果の検証です。実際に使用する場合には、学習に用いたデータとは異なるデータを用いますが、ここでは、簡単のため、同じデータを用います。
// 検証用データの読み込み(本チュートリアルでは同じデータを使用)
Dataset dataForClassification = FileHandler.loadDataset(new File("iris.data"), 4, ",");
分類には、分類用のデータのインスタンス(ここでは各行)毎に属性データを読み込み、分類結果を求めます。
Object predictedClassValue = rf.classify(インスタンスが入力される);
ここでは、dataForClassClassification内のすべてのインスタンスを分類対象としたいので、for文を用いることとします。また、分類結果と実際の分類を比較して、正解の場合(int correct)と不正解の場合(int wrong)をカウントすることとします。
// 正解と不正解の場合のカウント
int correct = 0;
wrong = 0;
// 分類と結果判定の実施
for (Instance inst : dataForClassification) {
Object predictedClassValue = rf.classify(inst);
Object realClassValue = inst.classValue(); // 評価用のデータから実際の分類値を取り出す
if (predictedClassValue.equals(realClassValue))
correct++;
else
wrong++;
}
最後に分類結果を出力します。
System.out.println("正しい分類数:" + correct);
System.out.println("誤った分類数:" + wrong);
以上でコードは完成です。プログラムを実行してみましょう。
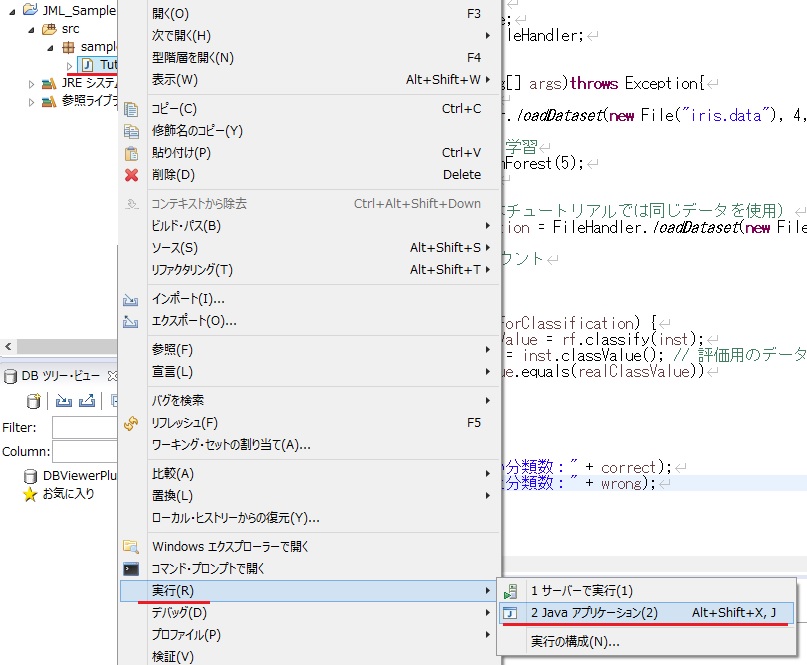
図 プログラムの実行

図 プログラムの実行結果
この実行では、全て正しく分類できたようです。決定木の作り方によっては、全てが正しくない場合もあると思います。
(ページの先頭へ)
■ 再近傍法を実装してみる
同様にして、再近傍法を実装することもできます。ランダムフォレスト法との違いは、分類器の作成のところと、分類のところだけです。以下に、違う部分を記載しますので、実際に動かしてみましょう。
// ランダムフォレストの作成と学習
//Classifier rf = new RandomForest(5);
//rf.buildClassifier(data);
// 再近傍用のインスタンスの作成と学習
Classifier knn = new KNearestNeighbors(5);
knn.buildClassifier(data);
評価のところの変更点は以下になります。
// Object predictedClassValue = rf.classify(inst);
Object predictedClassValue = knn.classify(inst);
変更したら実際に実行してみましょう。結果はどのようになりましたか。この例では、再近傍法の方が悪い結果が出るようです。

図 プログラムの実行結果