Internet achieved the environment of sharing information all over the world and made it possible for not only publishers but also individuals to publish their thought and works. It means that every individual should hold, manage and utilize one's own copyright. There is, however, no system to manage copyright information of all digital contents on the internet.
This paper proposes a new protocol and description language to create an architecture for copyright information management on the internet. This enables authors to attach copyright information to every object on the internet and make it referred from anywhere in the world. In addition, the copyright information described in this language can be interpreted by the program and the terms can be executed correcly at the user side by the program.
By designing and implementing prototype, we evaluate this architecture.
Table of Contents
Introduction Fundamental Design Design of Copyright Information Description Language Design of Copyright Information Transfer Protocol Design of Prototype Evaluation Conclusion Acknowledgment References
1. INTRODUCTION
In this section, we describe the overview of copyright information management architecture. Detail design of each conponents are discussed in the following sections.1.1 Goal
The goal of this architecture is to provide the environment whereCopyright holder can attach copyright information to every object on the internet Copyright information can be referred from anywhere when necessary Program can handle the object following the terms of Copyright information
1.2 Main conponets
We proposes following two components to archive the new architecture.Copyright Information Description Language (CIDL)This is a language to describe the copyright information in a intermediate format where an program can interpret it to adapt its behavior following the terms, also another program can translate it for users into their own language. This language is extensible to keep up with changes of laws and demand.
Copyright Transfer Protocol(CTP)
Assuming all of the objects on the internet are attached with the cipyright information described in the language above, this protocol identifies copyright information when an object is given by an URI and provides mechanism of registration and reference of copyright information.
1.3 Prototype and Evaluation
In order to evaluate the above description language and protocol, we implemented a prototype composed ofWe evaluate this description language, protocol and whole architecture of copyright information management by using this prototype on the "School of Internet" system [1], which is an experimental project to provide higher education environment on the internet.Copyright Information Builder which is a GUI based user interface to help them to write a copyright information in CIDL. Copyright information server which receives registration and retrieval requests for the specified object in Copyright Transfer Protocol. Sample object server which interprets the copyright information written in CIDL and decides the service level following the terms.
2. Fundamental design
In this section, we design description language, protocol and the prototype implementation of our new architecture. First, we define the elements which appear in this design. Second, we define the generic requirements to achieve the goals listed in 1.1. After this, we discuss the detail design of language, protocol and prototype.2.1 Elements
Elements which appear in this design are objects, copyright holders, copyright information and users.(1)objects
Identified by URI on the internet. They are works which have copyright.(2)copyright holders
Identified by email address on the internet. They hold copyright of objects(3)copyright information
Identified by the correspondence to URI of the object. This information is defined by copyright holders.
2.2 Requirements
Requirements to achieve the goal listen in 1.1, are the followings;In order to attach copyright information to every object on the internet, anyone have to be able to create copyright information. This copyright information should be translated into various languages because it receives access from all over the world. It is also necessary that programs can understand this information and provide appropriate access control.Copyright information should be widely distributed and managed in a scalable manner Every ordinary people who do not have enough legal knowledge to deal with legal paper can create a copyright information easily Copyright information should be able to be referred anytime and anywhere Programs can interpret copyright information and behaive according to it
According to these requirements, we propose Copyright Information Description Language (CIDL), to keep copyright information not in natural language but in abstracted form so that programs can interpret it.
In order to attach copyright information to countless objects on the internet, copyright information should be widely distributed and managed scalabily. Therefore, copyright information should be managed and operated by the organization which provides access service to the objects.
In this paper, we call the server managing copyright information "copyright
information server". This server returns responses when it accepts access
via the internet. We propose "Copyright Information Transfer Protocol"
as the interface of this copyright information server. It includes a protocol
to identify copyright information servers corresponding to the objects.
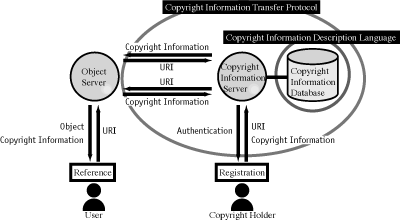
Figure1 Architecture
2.3 Architecture Overview
In this section, the process to achieve mechanism of registration and reference is described.Registration
RetrievalCopyright holder creates copyright information in CIDL Copyright holder requests to register it to copyright information server Copyright information server permits or rejects the request after autheticating the copyright holder
Given the URI if the object, the location of copyright information corresponding to the object can be identified by CTP. Details are described in the following section. Copyright information can be obtained from the identified server also by CTP.
This function could be implemented on both object servers (a server distributing objects, such as HTTP server, FTP server) and object clients such as Web browsers. It depends on where copyright information should be interpreted and which level of access control should be implemented.
3 Design of Copyright Information Description Language (CIDL)
In this section, we describe a design of Copyright Information Description Language. In this paper, we assume that the copyright information are to be described in accordance with the representative international consensus about copyright, Berne Convention, Universal Copyright Convention and WIPO Copyright Treaty. It is because objects on the internet are shared over countries, and we cannot describe copyright information in accordance with law established in one particular country.3.1 Requirement
Requirements for this description language are "Anyone can create copyright information easily", "Copyright information can be translated into various languages" and "Programs can interpret the copyright information".3.2 Basic functions
We define basic functions of description language as the followings.- Terms of use is described in accordance with the rights in the international conventions
- Description Language is flexible enough to the change of laws and demand.
3.3 Syntax
All copyright information is described as a set of lines composed of item names and values combined with "=". US-ASCII characters except special characters for control can be used in the item names and CR, LF or CRLF must be used at the end of lines. Values are in ISO-2022.3.4 Item
Items are a set of keywords describing copyright information. In this paper, we define the items in accordance with international conventions, but it is possible to change and add items when global consensus is established. In order to control this change, version information of this description language must be included in every copyright information.The following is a list of these items.
teble1 List of items category items explanation version inforamtion version version information of description language authors & copyright holders author author's name author_email author's email copyright_holder copyright holder's name copyright_holder_email copyright holder's email registrant registrant's name registrant_email registrant's email other_author name of author whose work is utilized in this work other_author_email email of author whose work is utilized in this work year year year of making works form of works form form of works status of copyright copyright_status status of copyright terms of authorizing authorizing to print works download authorizing to download works copy authorizing to make a copy of works translate authorizing to translate works perform authorizing to perform works except works of music perform_music authorizing to perform works of music broadcast authorizing to broadcast works recite authorizing to recite works to the public adapt authorizing to adapt works except works of music adapt_music authorizing to adapt works of music dis_compile authorizing to discompile works of program cinmatographic authorizing to change works to cinematographic communicate authorizing to communicate to the public distribute authorizing to distribute works rental authorixiong to rental works moral right prejudicial_use way to object to distortion, mutilation or other modification prejudicial to author's honor or reputation. authorship way to claim authorship way of notification notification way to notify the copyright information conditions of censent term term of authorization to utilize royality royality for authorization pay way to pay royrity guarantee guarantee conditions of guarantee legal proceedins law law applied in case of dispute court court having jurisdication of dispute
3.5 Values
Values are number or text. By specifying pre-defined numbers of text to the items above, terms can be clearly defined, including the prefered copyright information notification method.4 Design of Copyright Transfer Protocol (CTP)
In this section, we describe design of Copyright Information Transfer Protocol.4.1 Requirement
Requirements fot this protocol are "Copyright information should be widely distributed and managed scarably" and "All of copyright information on the internet should be refered to in the same way".4.2 Basic function
The basic functions to achieve the requirements above are the followings.Registration
1) Request to copyright information server
User sends a registration request to the copyright information server with its own certificate and information to register2) Authentication of copyright holder
Cipyright information server authenticates the requester by verifying the certificate, which confirms the copyright information server can trust the e-mail address shown by the requester, This process is necessary to prevent registration on pretense of copyright holders.3) Verification of copyright holder
Copyright information server obtains the copyright holder information of the object from the object server, then verify it with the shown e-mail address. When it matches, requester is confirmed as a real copyright holder and has a right to register the copyright information. It is necessary to allow only appropriate copyright holders of objects to register copyright information.Retrieval
1) Identification of copyright information server
Given the object in URI, user who tries to obtain the copyright information should be able to identify the copyright information server for the object.2) Once the server is identified, information can be retrieved by the protocol.
For both
All of transaction should be encrypted in order to prevent fabrications of copyright information.
4.3. Specification
In this section, we describe Copyright Information Transfer Protocol. All the transaction to the copyright information server are defined in this protocol. This protocol provides a connection of streaming type. We assign TCP Port 8150 for this protocol.This protocol requires an authentication process defined in SASL [2]. All the communication between server and client are encrypted using TLS[3].
Commands and status responses
This protocol uses command and staus responses. They are composed of
characters from the ASCII character set.
Commands consist of a command word and, which in some cases may be followed by a subcommand word and parameter. The following is a list of commands and its functions.
| HELLO | Command to check that a connected server is copyright information server or not. |
| VERSION | Command to check the vesion of copyright informaiton server. |
| REGISTER | Command to register the copyright information.
This has six subcommands of reg, get, ver, stat, mod and del. |
| RETRIEVE | Command to retrieve the copyright information. |
| SERVER | Command to get a list of object servers which are supported by copyright information server. |
The next digit in the code indicates the function.
table3 List of first digit of status responses 1xx Informative message 2xx Command ok 3xx Command was correct, but couldn't be performed for some reason. 4xx Command unimplemented, or incorrect, or a serious program error ccurred.
table4 List of second digit of status responses x0x Connection, version, and miscellaneous messages x1x Registration of copyright information x2x Reference of copyright information x3x Check of list of object servers x8x private implementation x9x Debugging output
5 Prototype Design and Implementation
In this section, we describe the design and implementation of the prototype system of CIDL and CTP, consist of the following 3 components;- Copyright information builder - an assistant system to write a copyright information in CIDL.
- Copyright information server - a server to communicate with CTP
- Object server - a server to interpret the copyright information of the object and perform the appropriate access control
5.1 Copyright Information Builder
Copyright nformation builder is a system to assist copyright holders to create copyright information in CIDL. This system achieves that anyone, even if he or she has no legal expertise, can create copyright information with ease and also without inconsistency.In this prototype, copyright information builder is implemented as a CGI program. A copyright holder goes through a sequence of questionnaire on the Web page to specify how to handle the object. At the end, all the answers are converted to copyright information in CIDL and returned to the copyright holder in text format which the holder can download for their future use.
5.2 Copyright information server
Copyright information server sends and receives data using Copyright Inforamtion Transfer Protocol and provide clients the access to the copyright information database. In this database, all the versions of copyright information of the object in the past are stored as well as its attribute information such as date, URI, copyright holder's e-mail address and status of registered copyright information.This server implements the full functionality of the copyright transfer protocol except security and authentication. In this prototype, https is used together with this server to complement those missing part.
On registration part, this server authenticates client with certificate and signature and encrypts communication chanel. After receiving URI and copyright information, it sends URI to object server and receives an e-mail addresses of copyright holders of the object. If this e-mail matches with the e-mail shown in client's certificate, this server register copyright information to copyright information database.
On retrieval part, this server receives URI form a requester such as a user or an object server, and returns its copyright information.
Copyright information server can serve the copyright information either only for one object server or a group of object servers depends on the management policy. In this prototype, one copyright server covers some object servers.
5.3 A sample object server
There are two kinds of models to utilize the copyright information depend on where to implement the interpretation component of the copyright information. One is to implement it in the object server side such as HTTPD or FTPD. Another model is to implement it in the object client side such as web browser.The former case, object server can verify the request with copyright server before providing the object to the requester. In latter case, client can implement more precise access control such as disabling printing function.
In this prototype, a sample object server is implemented which is sitting in front of the HTTPD as wrapper in order to verify all the request to the web server and perform access control and copyright information notification to the client appropriately.
In the architecture we propose, all the object server should be able to identify the copyright holders of all the object they serve as the copyright information server consult with the object server to obtain the copyright holder to the object in email address format. However, in the current environment, it is difficult to identify the real copyright holder of the object. In the prototype, file owner of the UNIX file sysmte is assumed to be a copyright holder. This sample object server gets the file owner uid and covert it to the email address by consulting with LDAP server running in the domain.
| client | disable client to use function of "Print" | |
| download | server | transfer objects in such format that client cannot save objects |
| client | disable client to use function "Save as" | |
| copy | client | disable client to use function "Copy" |
| translate | - | - |
| perform | client | disable client to perform the video |
| perform_music | client | disable client to perform the music |
| broadcast | - | - |
| recite | - | - |
| adapt | - | - |
| adapt_music | - | - |
| dis_compile | client | disable client to discompile the program |
| cinematograph | - | - |
| communicate | server | server inserts watermark to objects on server |
| distribute | server | server inserts watermark to objects on server |
| rental | server | server inserts watermark to objects on server |
| show_copyright | server | server receives copyright information and disable client to access without concent to conditions for authorizing, for example |
| client | client receives copyright information and functions as the above | |
| term | server | server authenticates client and does not permit to access if term of aithorization is exceeded. |
| royality | server | server charges client for royarity in some way and does not permit to access if it is not paid. |
5.4 Process
In this section, we describe a sample scenario how those 3 prototype components works together.Registration
- Copyright holder put data into Copyright information builder
- Copyright information builder creates a copyright information and returns it to a copyright holder
- Copyright holder request to connect copyright information server and send certificate and signature for authentication and encryption of routes
- If authentication is succeeded, copyright holder send URI and copyright information to copyright information server
- Copyright information server sends URI to object server and receives email address of the object owner.
- Copyright holder verifies the e-mail address shown in the certificate sent from copyright holder
- If it matches, Copyright information server registers URI, copyright information, e-mail address and date to the copyright information database
- User send URI to object server
- Object server sends URI to HTTP server and receives an object
- Object server sends URI to copyright information server and receives copyright information
- Object server interprets and translates copyright information and send the object and copyright information in the way defined by copyright information
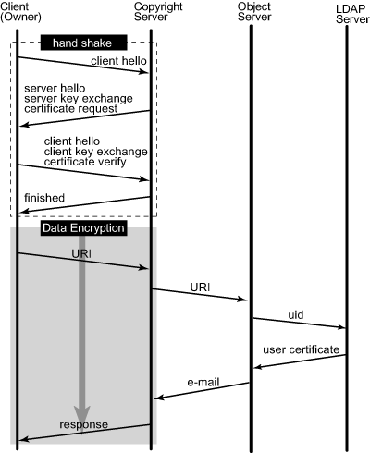
Figure2 : State Diagram of Registration |
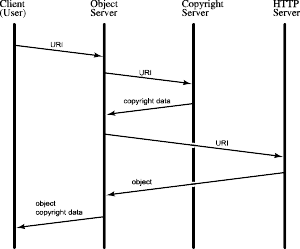
Figure3 : State Diagram of Retrieval |
6 Evaluation
In this section, we evaluate Copyright Information Description Language and Copyright Information Transfer Protocol based on implementation of the prototype in section 5. The criterion is the requirements defined in design.6.1 Sample
We select one course on the School of Internet (SOI) as a sample and evaluate the prototype on the assumption that we apply this prototype to the course and register the copyright information for all the video and materials of the course.Caurse
Caurse Name : Information Processing SystemContents
Faculty : Jun Murai
Performed at : KEIO University, Japan
Number of Lectures : 14
Total : 21 hours
Materials : 511 HTML filesCopyright Information
Video : 14 rm file (Real Video)
Japanese : about 800 byteWe create two kinds of copyright information, one for materials and one for video. This copyright information is shown both in English and in Japanese.
English : about 900 byte
Copyright Information Description Language : 377byte
In order to distinguish our architecture, we compare this prototype with a system which embed copyright information into objects such as Superdistribution [4].
6.2 Result
The following is the result of the evaluation.(1) Access control
We implemented that object server interprets copyright information and show it according to the copyright holdr's selection. On the other hand, Superdistribution also realize conditions of authorizing by interpreting it in "label reader" on client. Therefore, it is proved that both achieve the realization of conditions of authorizing and the way to show it.
(2) Coverage of Objects
On our system, any type of objects can be registered in the same way because of independency of the copyright information from the objects. On the Superdistribution system, it can embed the copyright information only into certain type of files.
(3) Modification of copyright information
Independency of copyright information also makes modification very easy. It is the same way with registration. In addition, as CTP allows directly-level registration, transactions for registration and modification are simpler. On Superdistribution system, it is necessary to embed copyright information into every object in the tree, instead.
(4) Translation to various languages
By describing the copyright information in CIDL, object server can translate it to various languages just by adding modules. On the other hand, on Superdistribution system, it is necessary to insert copyright in each language.
(5) Data Amount
On our system, data amount stored in copyright information server is
only 754 byte. As our system supports the directry level registration,
only 2 copyright information data described in CIDL covers all the video
and materials of one course. Also only one kind of copyright information
is needed to display in Japanese and English. On Superdistribution system,
data amount is 892.5kbyte, two kinds of copyright information for each
files. This is 1183 times of that on our system.
7 Conclusion
In order to achieve the environment where information sharing all over the world is entirely possible, it is also necessary to achieve the environment where copyright is managed appropriately regarding all digital contents published on the internet. In this paper, we proposed a new architecture for copyright information management and developed a new description language and protocol which compose the architecture.As a result, we achieved that copyright holders can attach copyright information to every object on the internet easily and make it referred from anywhere in the world, that conditions set by copyright holders in copyright information can be interpreted by the program and the program can perform the appropriate access control to the object and that copyright information can be widely distributed and managed scarably.
In addition, through the design and implementation of Copyright information builder, Copyright information server and a sample object server as a prototype, we evaluated the architecture and concluded the architecture and new protocol solves many of the copyright information management problem on the internet effectively.
However, there are some issues to be solved.
(1) Reuse of works
The coverage of this prototype is a part of transference form copyright
holders to users. The use of works, however, also continues after
transference and it is so important to control this reuse. By using watermark
together, for example, we will find a solution.
(2) Effectiveness of Description Language
It is necessary to check the effectiveness of Description Language
by applying to diverse copyright information. We evaluate it through experiments
on SOI in 1999 Spring term.
(3) Popularization
In order to achieve widespread implementation of this architecture,
it is necessary to establish a consensus among the entire internet community.
We have to grope the way to establish a consensus not only technically
but also legally in the future.
Solving these issues and improving this architecture, we will be able
to achieve the environment where copyright can be handled appropriately
on the internet.
8 Acknowledgment
School of Internet project is supported by WIDE Project. Number of colleagues at KEIO Univ. SOI research group have contributed to the work which we describe here. Thanks to members including Yuri Ijuin, Ken Sakaguchi, Keiichi Kawai, Tomohiro Muroi, Yasuharu Toyabe, Shoko Mikawa, and special thanks to Koji Ogawa for his help in writing this paper.9 References
- Keiko Okawa, Jun Murai, "School of Internet - A university on the Internet" INET98, 1998
- Myers, J., "Simple Authentication and Security Layer (SASL)", RFC 2222, Netscape Communications, October 1997
- Dierks, T., and C. Allen, "The TLS Protocol Version 1.0", Work in Progress.
- Ryoichi MORI, Masaji KAWAHARA and Yasuhiro OHTAKI, "Superdistribution : Electronic Technology for Copyright Management", http://sda.k.tsukuba-tech.ac.jp/SdA/reports/A-59/draft.html
- Yoko Murakami, "New Architecture of Copyright Information Management on Internet" graduation thesis, KEIO Univ. SFC, February 1998